Overview
Architectures
Explore
Test
Migrate
Scale
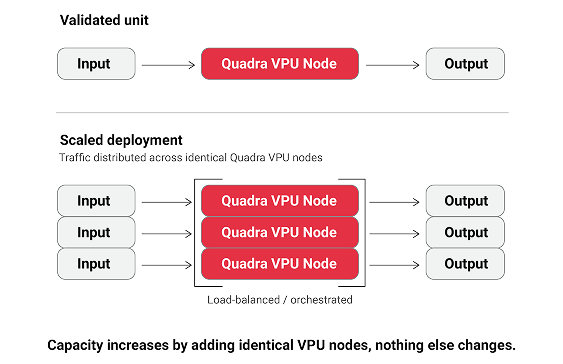
The purpose of this stage is to expand VPU deployment across workloads, regions, or environments with predictable economics and operational behavior.Scaling is not about tuning for peak demos. It’s about repeatability under pressure.
Scaling with VPUs means:
This is where general-purpose compute fails and purpose-built silicon holds.
Scaling follows the same principles as migration:
The goal is predictable growth, not heroic firefighting.
Typical reasons teams scale VPUs:
Scaling is driven by constraints, not ambition.
At scale, success looks like:
If scaling increases complexity, something is wrong.
When scaling is complete, you should have:
At this point, VPUs are now your infrastructure.
Continue reading through the sections.